3. Ergebnisse
Um festzustellen, ob die von uns vorgeschlagene Methode zur Charakterisierung verschiedener Lösungen und Potenzen geeignet ist, haben wir zunächst versucht, die Eigenschaften der Proben durch TEM-Analyse zu bestimmen.
3.1. TEM-Untersuchung
Die TEM ist ein wertvolles Instrument, das grundlegende Daten über die Organisation von Nanomaterialien liefert; dieses Wissen ist sehr wichtig für das Verständnis und die Entwicklung in der Materialwissenschaft sowie für Bereiche, die stark verdünnte Lösungen verwenden, die ebenfalls aus Nanostrukturen bestehen.
3.1.1. Aurum metallicum 6C
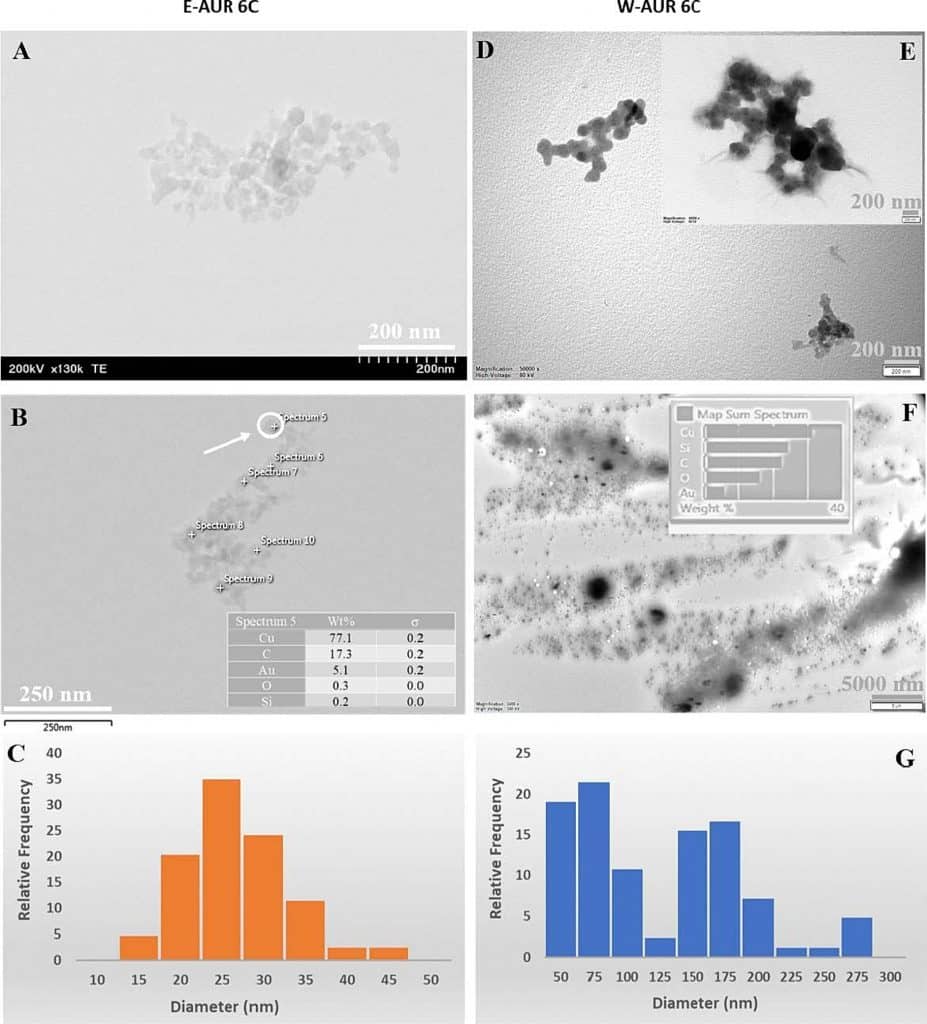
Abb. 1 zeigt mehrere TEM-Bilder, die mit zwei verschiedenen Geräten (siehe Abschnitt Methoden) für die 6C-Potenz von AUR aufgenommen wurden. Für die Probenvorbereitung wurden zwei verschiedene Medien verwendet – das erste Medium war eine 50 % v/v Ethanollösung, die für die in Rumänien analysierten AUR-Proben (E-AUR 6C) verwendet wurde. Das zweite Medium war gereinigtes Wasser, das für die in der Türkei untersuchten Proben verwendet wurde (W-AUR 6C).
Abb. 1. TEM-Daten für die 6C-Potenz von AUR. (A-C) TEM-Bilder und Histogramm der relativen Häufigkeit der Nanopartikelgrößen für die AUR-Proben auf Ethanolbasis und (D-G) für die Proben auf Wasserbasis; Einschub – EDX-Daten für die markierten Punkte oder das Summenspektrum.
Trotz der zugrundeliegenden Unterschiede bei den Lösungsmitteln sind die erhaltenen TEM-Bilder hinsichtlich der Form der Nanopartikel recht ähnlich. Die Größe der Nanopartikel hängt jedoch von der Art des Lösungsmittels ab. Die Histogramme der beiden Proben zeigen, dass die Nanopartikel bei E-AUR 6C kleiner sind als bei W-AUR 6C (Abb. 1C und G), was wahrscheinlich darauf zurückzuführen ist, dass Ethanol als Stabilisierungsmittel wirksamer ist als Wasser. Die EDX-Daten (Einschübe in Abb. 1 und Abb. S3 und S4) zeigen vergleichbare Anteile an Gold (Au) in beiden Proben und das Vorhandensein von Silizium (Si) und Sauerstoff (O) (das Kupfer (Cu) stammt aus dem Gitter).
3.1.2. Aurum metallicum 30C
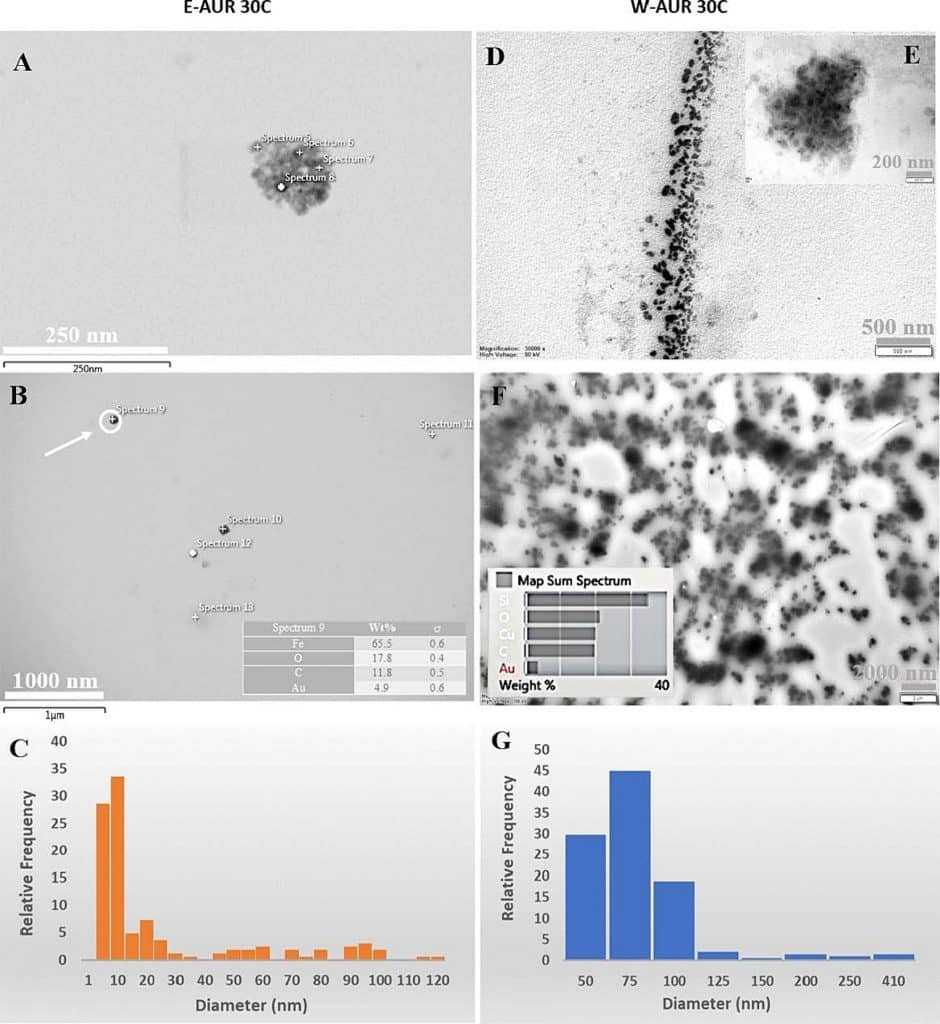
Außerdem wurde die 30C-Potenz von AUR untersucht; Abb. 2 und Abb. S5-S8 zeigen die TEM-Bilder, EDX-Daten und TEM-EDX-Mapping-Ergebnisse für diese Potenz. Hier sind die Ähnlichkeiten zwischen den beiden Proben, E-AUR 30C und W-AUR 30C, hinsichtlich der Form der Nanostruktur und des
Auftretens von Verunreinigungen erwähnenswert.
Abb. 2. TEM-Daten für die 30C-Potenz von AUR. (A-C) TEM-Bilder und Histogramm der relativen Häufigkeit der Nanopartikelgrößen für die AUR-Proben auf Ethanolbasis und (D-G) für die Proben auf Wasserbasis; Einschub – EDX-Daten für die markierten Punkte oder das Summenspektrum.
Wie im vorherigen Fall, der Potenz 6C, ist die Größe der Nanopartikel/Nanostrukturen der Potenz 30C bei E-AUR tendenziell kleiner als bei W-AUR (Abb. 2C und G); dieses Verhalten lässt sich durch die Fähigkeit von Ethanol erklären, als effizientes Stabilisierungsmittel zu wirken. Darüber hinaus zeigen die Histogramme in Abb. 1 und Abb. 2, dass die Nanostrukturen in E-AUR 30C kleiner sind als in E-AUR 6C und im Vergleich zu den wässrigen Proben um mehr als 150 nm abnehmen; diese großen Strukturen sind in W-AUR 6C deutlich zu erkennen, während sie in der W-AUR 30C-Probe nur in Spuren sichtbar sind. Diese signifikante Veränderung zwischen den Profilen der beiden Potenzen 6C und 30C tritt nach dem Potenzierungsprozess auf, der mehrere aufeinanderfolgende Verdünnungen und Sukzessionen umfasst.
3.1.3. Aurum metallicum 200C
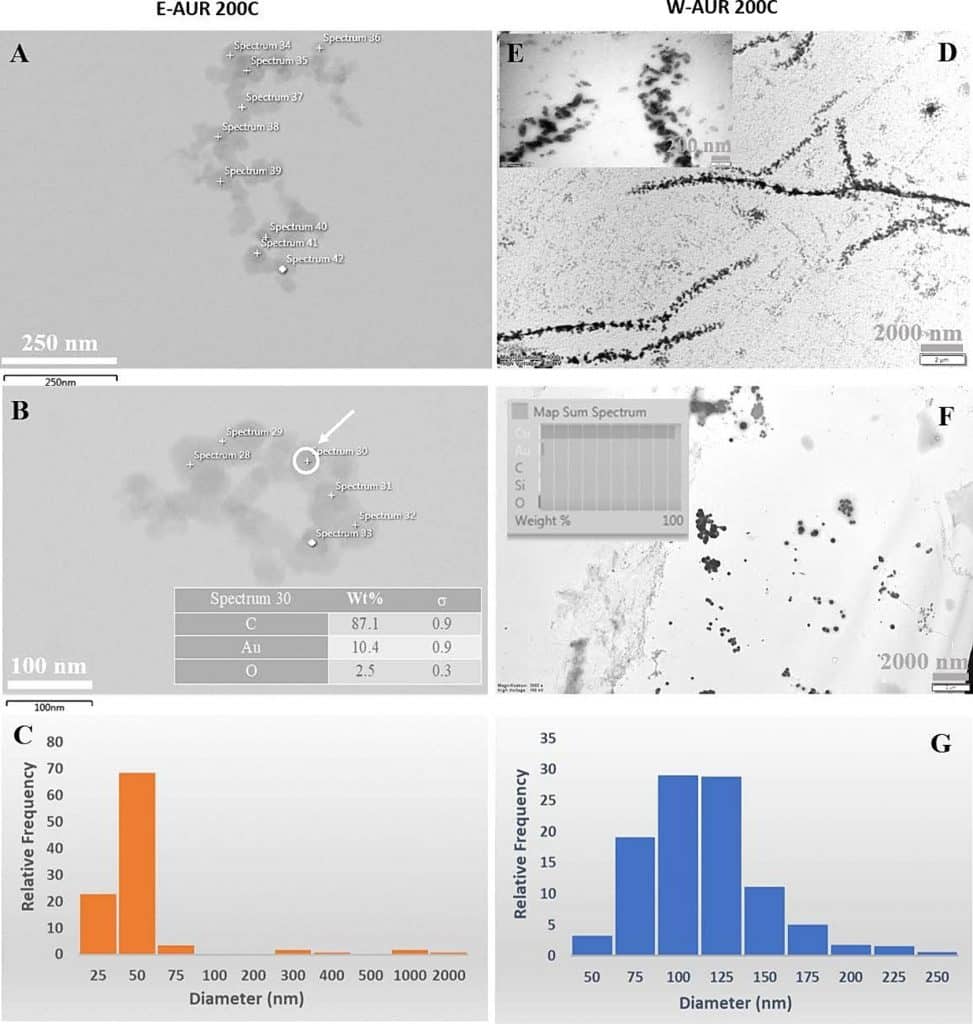
Die Merkmale der 200C-Potenz sind in Abb. 3 und Abb. S9-S11 dargestellt und wurden durch die Analyse von zwei Proben (E-AUR 200C – hergestellt mit einer wässrigen 50 % v/v Ethanollösung und W-AUR 200C
- nur mit gereinigtem Wasser hergestellt) ermittelt.
Abb. 3. TEM-Daten für die 200C-Potenz von AUR. (A-C) TEM-Bilder und Histogramm der relativen Häufigkeit der Nanopartikelgrößen für die Proben auf Ethanolbasis und (D-G) für die Proben auf Wasserbasis; Einschub – EDX-Daten für die markierten Punkte oder das Summenspektrum.
Die allgemeine Tendenz, die für die Potenzen 6C und 30C beobachtet wurde, ist auch hier vorhanden; genauer gesagt ist die Größe der Nanostrukturen in der Probe E-AUR 200C kleiner als in W-AUR 200C, wie aus den Histogrammen in Abb. 3 hervorgeht. Darüber hinaus sind die Nanopartikel in beiden 200C-Proben größer als die in der 30C-Potenz beobachteten Nanopartikel und unterscheiden sich in Größe und Form stark von den Nanopartikeln in der 6C-Potenz (Abb. 1, Abb. 2, Abb. 3).
Abb. 3B zeigt eine ausgeprägte Organisation und das völlige Fehlen von Verunreinigungen innerhalb einiger AUR 200C-Cluster-Assemblies. Darüber hinaus zeigen beide AUR 200C-Proben eine bevorzugte verzweigte Anordnung (Abb. 3A und D), und das Vorhandensein kleiner Mengen von Verunreinigungen wie Si und Fe in diesen Clustern wird durch die EDX-Daten in der Beilage zu Abb. 3 und in den Abbildungen S9 und S11B nachgewiesen.
3.2. Raman-Spektroskopie und Deep-Learning-Untersuchungen
Nach der Durchführung der TEM-Studien kann eine schnelle und zerstörungsfreie Technik wie die Raman-Spektroskopie für die Analyse der untersuchten Lösungen in Betracht gezogen werden. Da bei den wässrigen Proben im TEM größere Anordnungen beobachtet wurden und die Raman-Eigenheiten von Wasser-Ethanol-Lösungen berücksichtigt wurden, wurde die Raman-Spektroskopie nur auf die wässrigen Lösungen angewandt. Ziel war es, die Umwandlungen zu untersuchen, die in drei Gruppen/Kategorien auftreten: PW, UW und AUR. PW wird im Allgemeinen für die Zubereitung homöopathischer Mittel verwendet, während UW eine teilweise gereinigte Form von Wasser ist; diese Wassertypen weisen unterschiedliche Eigenschaften auf. Die PW-Proben weisen eine niedrige Leitfähigkeit (0,7-0,88 µS/cm) und einen geringen Ionengehalt auf (NO3- <0,2 ppm, Al < 3-5 ppb, Schwermetalle insgesamt 0,00682 ppm), während die UW-Proben eine höhere Leitfähigkeit (196 µS/cm) und höhere Konzentrationen an verschiedenen Ionen (Nitrat, Bikarbonat, Natrium usw.) aufweisen. Weitere Einzelheiten finden Sie im Abschnitt Material und Methoden.
Die Potenzierung wurde auf PW-, UW- und AUR-Proben angewandt, die an drei verschiedenen Tagen hergestellt wurden, um drei Chargen potenzierter Proben in den Potenzen 6C, 30C und 200C zu erhalten. PW und UW werden im Allgemeinen nicht für die Vermarktung potenziert; das Potenzierungsverfahren wurde nur für diese Studie angewandt. So wurden 33 Proben mittels Raman-Spektroskopie analysiert. Jede Probe wurde an 5 Punkten analysiert, um repräsentative Daten für die untersuchten Lösungen zu erhalten. Insgesamt wurden 165 Raman-Spektren (Bereich 180-4000 cm-1) der Klassifizierungsstudie unterzogen. Die rohen und mit bg vorbehandelten Raman-Spektren, die während dieses Experiments für verschiedene Potenzierungsstufen (6C, 30C und 200C) der untersuchten Probentypen (PW, UW und AUR) erhalten wurden, sind in den Abbildungen S12-S17 dargestellt.
3.2.1. Klassifizierung aller Klassen mit Deep Learning unter Verwendung des GRU-Modells
Die Ergebnisse der Raman-Spektralklassifizierung für die 11 verschiedenen Klassen, die mit dem trainierten GRU-Modell erzielt wurden, sind in Abb. 4 dargestellt; es wurden sowohl unbehandelte als auch bg-vorbehandelte Datensätze berücksichtigt.
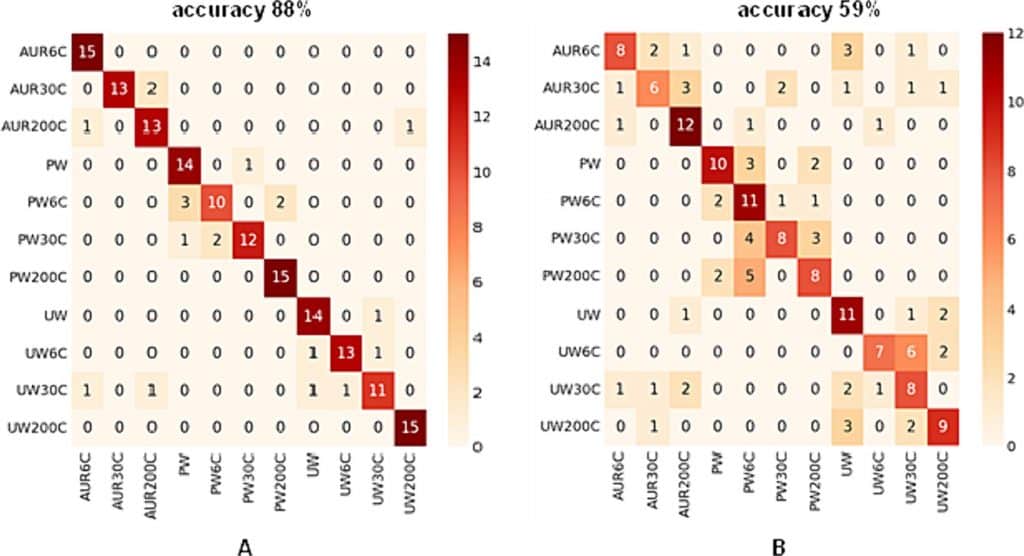
Abb. 4. Konfusionsmatrix des GRU-Modells für (A) unvorbehandelte und (B) bg-vorbehandelte Daten aller untersuchten Kategorien
Die Konfusionsmatrix wird angezeigt, um einen Überblick über die Anzahl der Fälle zu geben, in denen das GRU-Modell das Ergebnis richtig oder falsch vorhergesagt hat. Das Modell beweist eine sehr gute Erkennungsleistung beim Vergleich der drei untersuchten Kategorien; so zeigt es eine große Effizienz bei der Unterscheidung zwischen den Kategorien AUR, PW und UW, wenn unbehandelte Raman-Daten betrachtet werden (Abb. 4A). In diesem Fall kann eine Genauigkeit von 88 % (Tabelle 1) festgestellt werden; dieser Wert kann als sehr gut angesehen werden, insbesondere wenn die großen Ähnlichkeiten zwischen den untersuchten Klassen berücksichtigt werden. Dieser Wert, der etwas unter 90 % liegt, ist größtenteils das Ergebnis falscher Zuordnungen, die für unterschiedliche Potenzierungsstufen oder Referenzproben derselben Kategorie generiert wurden; nur drei falsche Zuordnungen wurden zwischen den drei untersuchten Klassen – AUR, PW, UW – registriert (eine Probe von AUR200C wurde UW200C zugeordnet und zwei Proben von UW30C wurden AUR6C bzw. AUR200C zugeordnet).
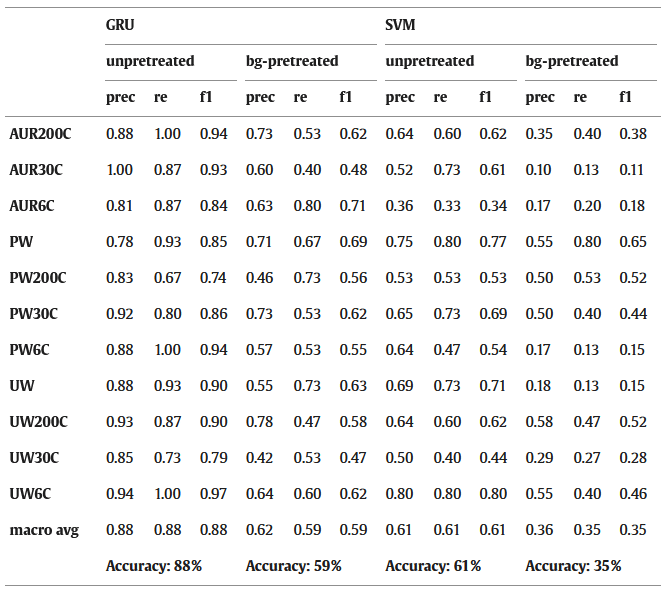
Tabelle 1. Klassifizierungsergebnisse, die mit unbehandelten und baseline-subtrahierten (bg-vorbehandelten) Raman-Daten erzielt wurden.
Bei der Kategorie AUR waren die anderen drei falschen Zuordnungen also auf die Ähnlichkeiten zwischen verschiedenen Potenzierungsgraden innerhalb der Gruppe zurückzuführen. Ein ähnliches Verhalten wurde auch bei den Gruppen PW und UW beobachtet. Es gab keine Fehler im Zusammenhang mit der Unterscheidung von PW- und AUR- oder UW-Proben. Innerhalb der PW- und UW-Gruppen wurde eine korrekte Erkennung für die Potenzstufe 200C beobachtet, während für die anderen Potenzierungsstufen bis zu 5 Proben falsch zugeordnet wurden (dieses Maximum wurde in der PW6C-Klasse erreicht).
Bei der Anwendung des GRU-Modells auf den mit bg vorbehandelten Datensatz ergab sich jedoch eine Genauigkeit von nur 59 % (Abb. 4B und Tabelle 1). Die meisten falschen Klassifizierungsergebnisse wurden innerhalb der drei untersuchten Gruppen erzielt, aber es gab auch einige falsche Zuordnungen zu Proben außerhalb der richtigen Gruppe. Diese Ergebnisse zeigen, dass die schlechte Erkennungsleistung des Modells auf den Informationsverlust zurückzuführen ist, der bei der Anwendung der Hintergrundsubtraktion auf die Ramandaten auftrat. Die Gruppen AUR und UW scheinen am stärksten betroffen zu sein (Abb. 4B).
Tabelle 1 enthält eine eingehende Analyse der Leistungswerte des vorgeschlagenen Ansatzes. Die Werte für Präzision, Recall und f1 wurden für jede Klasse unabhängig voneinander ermittelt. Die Ergebnisse de
Experimente zeigen, dass die Makro-f1-Werte für die beiden Datensätze 0,88 und 0,59 betragen. Bemerkenswert ist, dass die Kategorien PW, PW6C, PW30C und PW200C in beiden Datensätzen stabile Erkennungsraten aufweisen. Wenn die Wiedererkennungswerte berücksichtigt werden, neigt das Modell dazu, die Klassifizierungsgenauigkeit von UW30C-Proben zu unterschätzen. Aus den Ergebnissen lässt sich ableiten, dass die Unterscheidungskraft dieses Modells für die UW-Daten insgesamt etwas begrenzt ist. Darüber hinaus wird in dieser Arbeit die Verwendung eines bekannten Ansatzes des maschinellen Lernens, insbesondere der Support-Vektor-Maschinen (SVM), für die Kategorisierung von Raman-Daten untersucht. Verglichen mit der Deep-Learning-Methode (GRU) lieferte die traditionelle maschinelle Lerntechnik (SVM) die niedrigsten Genauigkeitswerte für die beiden Datensätze.
In Anbetracht dieser Ergebnisse wurde eine eingehendere Untersuchung durchgeführt, und zwar wurde ein intelligenter Ansatz zur Datenerweiterung verwendet, um den Datensatz zu vergrößern. So wurde jedes Raman-Spektrum mit Hilfe einer spektralen Segmentierungsstrategie in kleinere Segmente unterteilt. Die Größe der Segmente wurde auf 1 × 1024 festgelegt. Wenn die Stichprobengröße beispielsweise auf 1 × 12733 festgelegt wird, werden insgesamt etwa 12 einzigartige Segmente erfasst. Der Originaldatensatz enthält 15 Instanzen für eine bestimmte Klasse. Nach Abschluss des Segmentierungsverfahrens wird der Datensatz auf 1980 × 1024 verkleinert und besteht aus 11 verschiedenen Klassen. Die Anzahl der Stichproben pro Klasse beträgt somit 180. Der Datensatz wird dann aufgeteilt, wobei 80 % für das Training und der restliche Teil für Testzwecke reserviert wird. Die fünffache Kreuzvalidierung wurde angewendet, um die Leistung unseres GRU-Modells auf den erhaltenen Segmentierungsdatensätzen zu messen. Bei diesem Ansatz wurde festgestellt, dass ein direkter Zusammenhang zwischen der Erhöhung der Segmentgröße und der Abnahme der Leistung besteht. Die in Abb. S18 und Tabelle S1 dargestellten experimentellen Ergebnisse, die durch Einbeziehung der Stichproben aus den Testdatensätzen erzielt wurden, zeigen, dass unser GRU-Modell eine hohe Genauigkeit von 99,45 % für unbehandelte Daten und eine perfekte Genauigkeit von 100 % für bg-vorbehandelte Daten über 11 Klassen hinweg erreicht. Auch wenn weitere Untersuchungen, z. B. mit einer größeren Anzahl von Stichproben, durchgeführt werden müssen, bevor die spektrale Segmentierungsstrategie als die am besten geeignete für Experimente mit einer großen Anzahl von Klassen vorgeschlagen werden kann, kann diese Strategie als wertvoller Ansatz zur Datenerweiterung für unsere Art von Daten betrachtet werden.
3.2.2. Klassifizierung der Potenzen innerhalb jeder Gruppe mit Deep Learning unter Verwendung des GRU-Modells
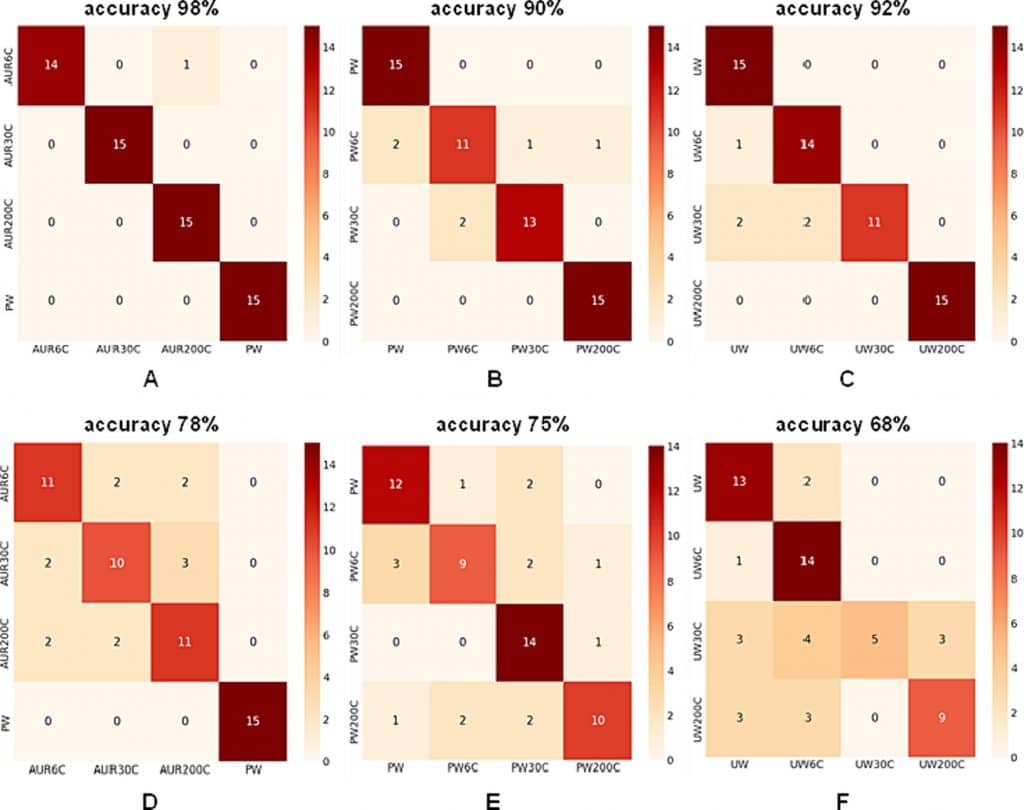
Die mit der DL-Methode erzielte Erkennungsrate innerhalb jeder Kategorie (AUR 6C, AUR 30C, AUR 200C, PW), (PW, PW 6C, PW 30C, PW 200C) und (UW, UW 6C, UW 30C, UW 200C) wurde anhand von unbehandelten und bg-vorbehandelten Raman-Daten analysiert und die Ergebnisse hinsichtlich der Leistungswerte verglichen. Abb. 5 veranschaulicht die Ergebnisse der Experimente nach Anwendung der geschichteten 15-fachen Kreuzvalidierung (CV).
Abb. 5. Leistung des Deep-Learning-Modells zur Bewertung der Unterscheidung innerhalb jeder Gruppe unter Verwendung von (A-B-C) unbehandelten und (D-E-F) bg-vorbehandelten Daten.
Um die Proben für Validierungs- und Trainingszwecke zuzuordnen, haben wir eine 15-fache Aufteilung vorgenommen, wobei 11 Proben für die Validierung und die restlichen Proben für das Training ausgewählt wurden. Für die AUR-Gruppe wurde die nicht potenzierte PW-Klasse als Referenz verwendet.
Im Fall von AUR und PW zeigen die erstellten Konfusionsmatrizen, dass 98 % und 78 % Genauigkeit erzielt wurden (Abb. 5A und D). Die Ergebnisse zeigten Genauigkeiten von 90 und 75 % für die PW-Gruppe (Abb. 5B und E), während für die UW-Gruppe Genauigkeiten von 92 und 68 % erzielt wurden (Abb. 5C und F). Im Allgemeinen weisen die Gruppen PW6C und UW30C im Vergleich zu den anderen Klassen eine geringe Leistung auf. Nach einer allgemeinen Analyse wird deutlich, dass die AUR-Gruppe die wenigsten falschen Klassifizierungen aufweist und dass die meisten Fehlklassifizierungen aufgrund der großen Ähnlichkeit zwischen den Klassen 6C und 30C auftreten.
3.2.3. Klassifizierung innerhalb der gleichen Potenzierungsstufe mit Deep Learning unter Verwendung des GRU-Modells
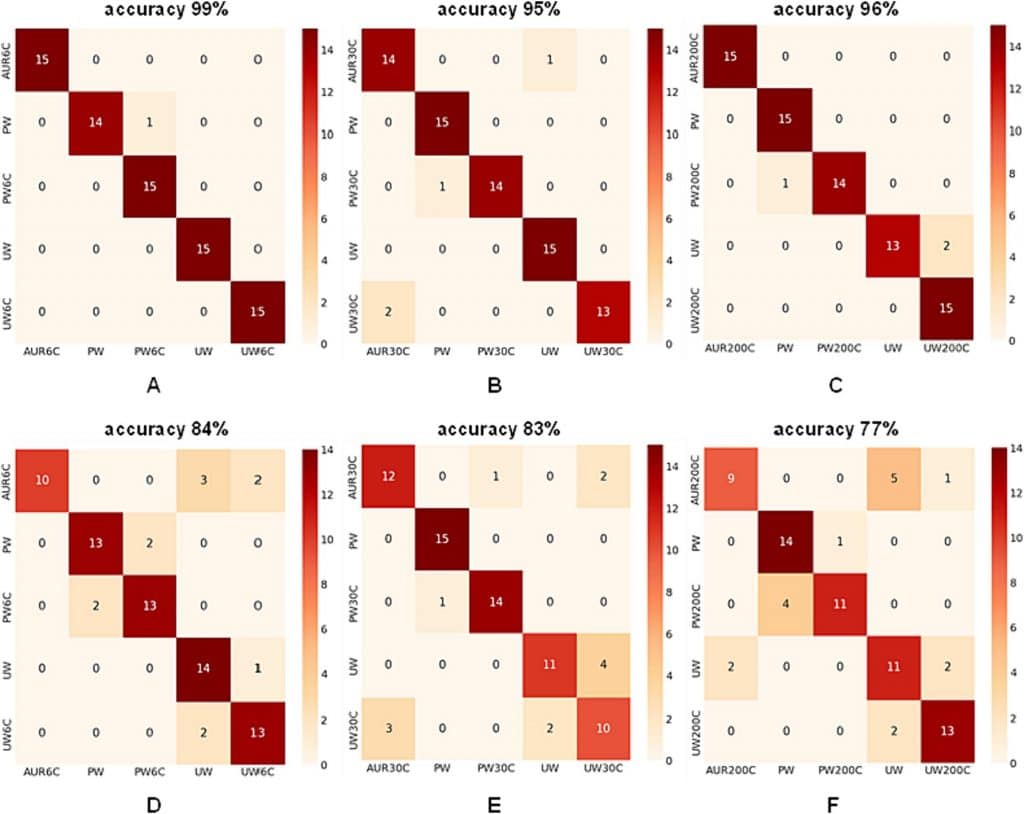
Zusätzlich wurde die Leistung von DL bei der Unterscheidung von Klassen innerhalb der gleichen Potenzierungsstufe auf der Grundlage ihrer Raman-Spektren analysiert (Abb. 6). Bei der Kategorisierung der Potenzierungsstufen wurden fünf Klassen berücksichtigt, darunter die potenzierten AUR-, PW- und UW-Proben sowie die nicht potenzierten PW- und UW-Proben als Referenz. Die Analyse der Ergebnisse zeigte, dass das GRU-Modell für die 6C-Potenz Genauigkeitswerte von 99 % (unbehandelt) und 84 % (bg-vorbehandelt) lieferte. Für die 30C-Potenz wurden ebenfalls Genauigkeitswerte von 95 % (unbehandelt) und 83 % (bg-vorbehandelt) ermittelt. Für die 200C-Potenz erbrachte das GRU-Modell Genauigkeitswerte von 96 % (unbehandelt) und 77 % (bg-behandelt). Die beste Leistung des GRU-Modells wurde also bei niedrig verdünnten Lösungen (6C) beobachtet.
Abb. 6. Leistung des Deep-Learning-Modells für die Bewertung der Unterscheidung innerhalb jeder Potenzierungsstufe unter Verwendung von (A-B-C) unbehandelten und (D-E-F) mit bg vorbehandelten Daten.